opencode使用系列课程连载(7): 完成一个真实开发任务,从需求到代码落地
Excerpt
我用 OpenCode 完成一个真实开发任务:从需求到代码落地前面几篇,我们把 OpenCode 的基础、进阶、性能优化、Skills、MCP,以及我自己日常怎么用它,都聊了一轮。再继续数功能,就有点像给瑞士军刀数刀片了。所以这一篇不讲概念,直接上工地。我拿一个真实的小任务来讲:svg-renderer。它现在就在我的写作目录旁边,不是为了写文章临时编出来的案例。它不是什么宏大项目,也不是一个准备
我用 OpenCode 完成一个真实开发任务:从需求到代码落地
前面几篇,我们把 OpenCode 的基础、进阶、性能优化、Skills、MCP,以及我自己日常怎么用它,都聊了一轮。
再继续数功能,就有点像给瑞士军刀数刀片了。
所以这一篇不讲概念,直接上工地。
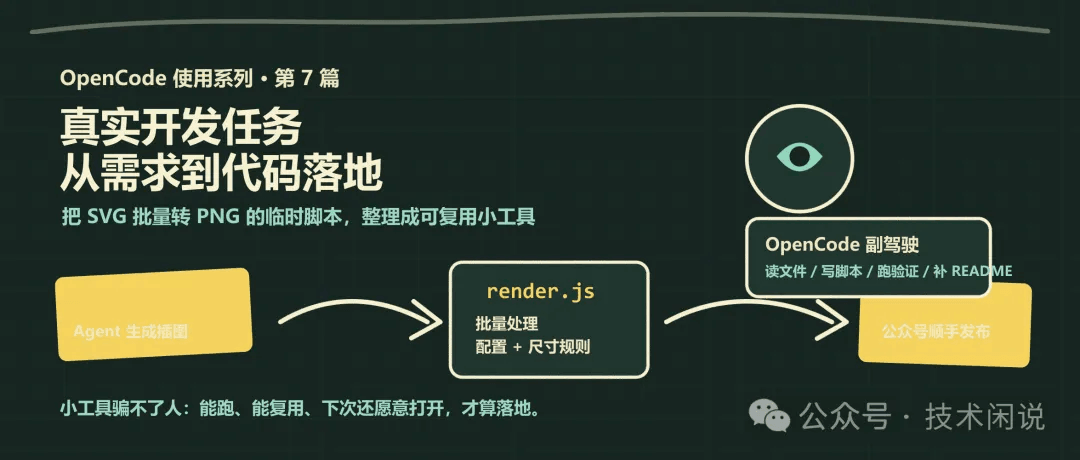
我拿一个真实的小任务来讲:svg-renderer。它现在就在我的写作目录旁边,不是为了写文章临时编出来的案例。
它不是什么宏大项目,也不是一个准备融资的 SaaS。它就是一个很朴素的小工具:把 SVG 图片批量转成 PNG。
但正因为它小,反而更适合讲 OpenCode 在真实开发里到底怎么用。需求从哪里来,任务怎么拆,代码怎么改,哪里该让 AI 干,哪里必须人来拍板,这些细节都躲不开。
大项目容易讲虚,小工具骗不了人。
需求从哪来:SVG 能看,但公众号要 PNG
这个工具的来源很简单。
我在写公众号文章时,会让 Agent 帮我生成一些插图。比如流程图、对比图、架构图、封面草图。Agent 很喜欢生成 SVG,这事其实挺合理:SVG 是文本格式,方便生成,也方便后续修改,浏览器直接打开就能看。
问题是,公众号发文时,真正顺手的插图格式还是 PNG。
SVG 在本地看着挺好,一到发布流程里就不那么舒服了。你要么手工截图,要么找工具转换,要么打开各种在线网站。一次两次还行,图一多就开始烦。
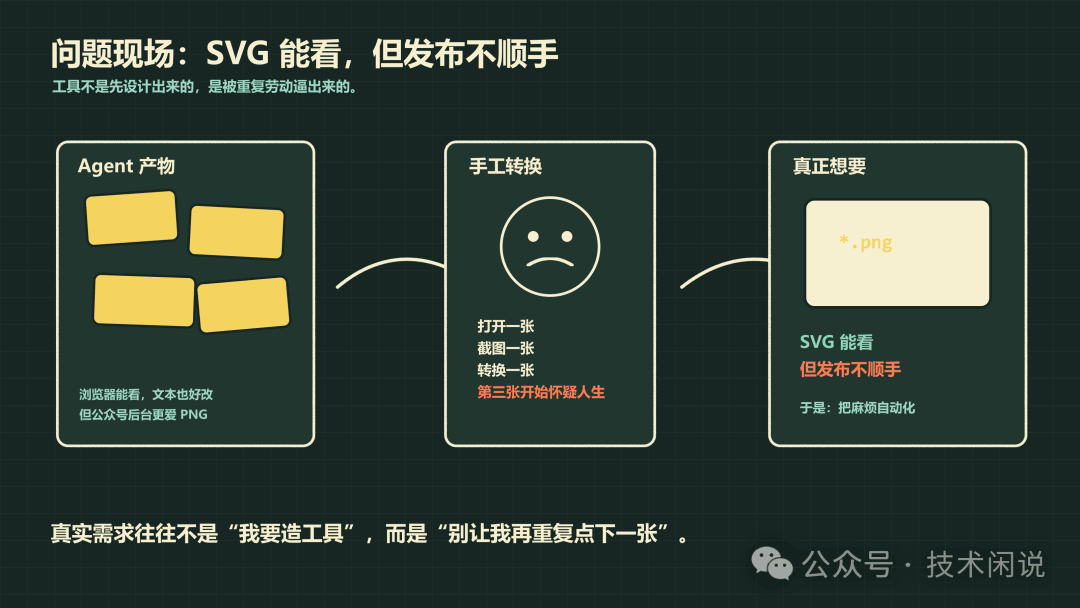
第六篇里我就有一批插图:封面、使用场景图、编码工作流、上下文管理、提速技巧……这些图如果一张张手工转,技术含量不高,但非常消耗耐心。
当时我的第一反应并不是“我要做一个工具”。
更真实一点说,是“别让我再点下一张了”。
程序员最怕的不是复杂问题。
复杂问题至少还显得自己有价值。
最烦的是那种“明明很简单,但要重复做十遍”的事。它不难,但它磨人。
于是就有了 svg-renderer:一个把文章目录里的 assets/*.svg 批量转成 assets/png/*.png 的小工具。
这就是整个需求的起点。
不是我突然想写一个图片处理框架,也不是为了研究 sharp。就是写文章时被格式转换烦到了,于是顺手把这件事自动化。
很多内部小工具,都是这么长出来的。
第一版:先写个能转一张图的脚本
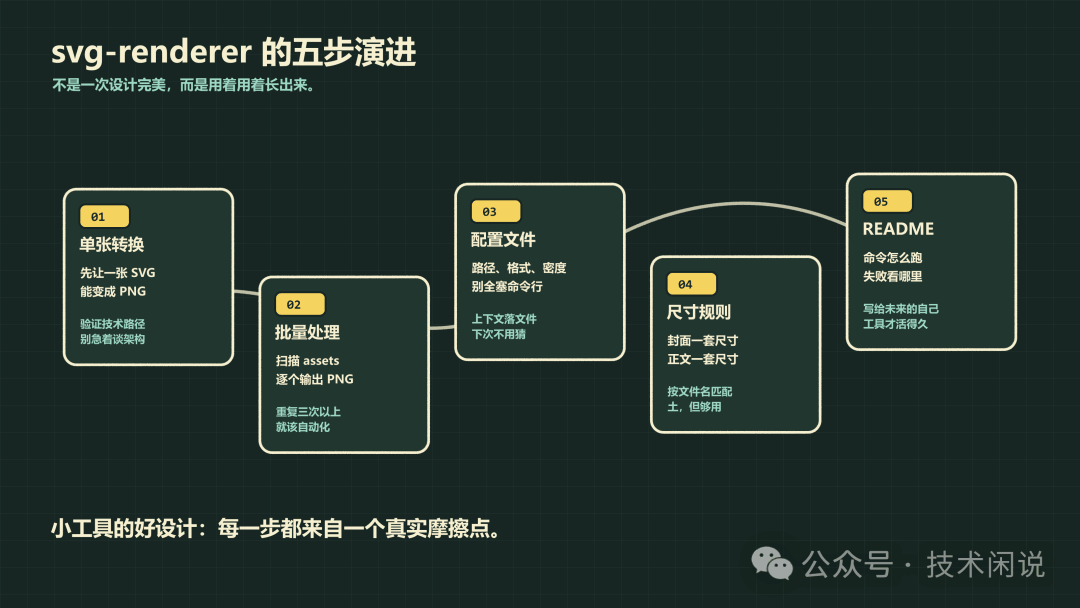
第一步很朴素:先让一张 SVG 能转成 PNG。
这个阶段我不会急着设计配置文件,也不会一上来考虑扩展性。老程序员都知道,第一版最好别太漂亮。太漂亮容易让你误以为自己已经想清楚了。
这时候最重要的问题只有一个:这条路通不通?
用 Node.js 加 sharp 就够了。
大概思路是:读一个 SVG 文件,指定输出尺寸,写成 PNG。
const sharp = require('sharp');
await sharp('input.svg', { density: 288 })
.resize(3200, 1800, { fit: 'fill' })
.png({ compressionLevel: 9 })
.toFile('output.png');
这段代码没什么神秘的。
但它验证了一件事:这条技术路径可行。
我一直觉得,做小工具的时候,不要一开始就追求“架构优雅”。先把最小闭环跑通。输入是什么,输出是什么,中间工具链能不能工作,这些比目录结构更重要。
OpenCode 在这个阶段适合干什么?
它适合帮我快速查清楚现有目录、生成最小脚本、把 sharp 的调用方式写出来。
但它不适合替我决定“这个工具到底要不要做”。这个判断必须人来做。
因为 AI 不知道你是不是真的被这个问题烦了三次。
这一阶段,我大概会这样提示 OpenCode:
我这里有一张 SVG 图片,想把它转成公众号更方便用的 PNG。
你先看一下当前目录结构,帮我写一个最简单的 Node.js 脚本,把这张 SVG 转成 PNG。能跑起来就行,先别搞太复杂。
第二版:一张张转太蠢,改成批量处理
单张转换跑通以后,很快就会遇到第二个问题:一张张转还是太蠢。
公众号文章里的图通常不是一张。
封面一张,正文插图几张,流程图一张,对比图一张,有时候还有架构图和总结图。你每张都手工指定输入输出路径,命令行敲到第三张就开始怀疑人生。
所以第二版要做批量处理。
工具不再接收某一个具体 SVG,而是扫描一个目录,找到里面所有 .svg 文件,然后逐个输出同名 .png。
这一步的关键不是技术难度,而是工作习惯。
如果一个动作会重复三次以上,我就会开始考虑它是不是该自动化。
不是因为我勤快,恰恰相反,是因为我懒得很稳定。
批量处理以后,使用方式就变成了:
node render.js --config "C:\Users\andy1\work\公众号创作\5.1opencode使用系列教程第6篇\render.config.json"
执行后,终端会输出类似这样的结果:
我用 OpenCode 完成一个真实开发任务:从需求到代码落地OK cover-opencode-workflow.svg -> cover-opencode-workflow.png [2350x1000] via cover
OK figure-1-opencode-usage-map.svg -> figure-1-opencode-usage-map.png [3200x1800] via default
DONE success=6 failed=0 output=C:\Users\andy1\work\公众号创作\5.1opencode使用系列教程第6篇\assets\png
这类输出很重要。
很多人写脚本�,只要它悄悄跑完就算成功。但真实使用时,你需要知道它到底处理了哪些文件,成功几个,失败几个,输出到哪里。
没有反馈的自动化,像一个闷头干活但从不汇报的同事。你不能说他没干活,但你心里没底。
这时候,我会把提示词往前推一步:
刚才单张 SVG 转 PNG 已经能跑了。
但我现在有一批 SVG 图片,一张张指定输入输出太麻烦。你帮我把脚本改成批量处理:读取一个目录里的所有 SVG,然后输出成同名 PNG。
最好终端里能告诉我每张图是否转换成功。
第三版:命令行参数太烦,配置文件上场
批量处理解决了“一张张转”的问题,但很快又冒出一个新问题:每次手工指定路径和参数也烦。
这就是小工具最真实的生长方式:不是一开始设计出完整形态,而是你用着用着,新的摩擦点自己冒出来。
输入目录在哪里?输出目录在哪里?输出格式是什么?渲染密度是多少?PNG 压缩参数怎么设?
这些都放到命令行里,不是不行,就是用起来很难受。
于是第三版加了配置文件。
配置文件的价值,不只是少敲几个参数。更重要的是,它把“这篇文章的图片转换规则”保存下来了。
{
"inputDir": "./assets",
"outputDir": "./assets/png",
"formats": ["png"],
"render": {
"density": 288,
"fit": "fill",
"png": {
"compressionLevel": 9,
"adaptiveFiltering": true,
"palette": false
}
}
}
这样下次再处理同一篇文章的图片,不需要重新回忆参数。
配置文件还有一个好处:它让 OpenCode 更容易理解任务。
你不用在提示词里反复解释“输入目录是 assets,输出目录是 assets/png,封面尺寸是多少,正文尺寸是多少”。这些信息放进配置文件,OpenCode 读一下就能建立上下文。
这也是我现在用 OpenCode 的一个基本习惯:能落到文件里的上下文,就不要全靠嘴说。
嘴说会丢,文件会留。
当然,文件也会乱。所以 README 后面还得补。
到这一步,我会这样跟 OpenCode 说:
现在批量转换能用了,但输入目录、输出目录、图片尺寸、渲染参数都写在脚本里,每次换文章目录都要改代码,不太顺手。
你帮我加一个配置文件,把这些经常变化的参数放进去。脚本运行时通过 --config 指定配置文件。
第四版:封面和正文图尺寸不同,规则系统来了
配置文件解决了路径和通用渲染参数,但还有一个更实际的问题:封面和正文图尺寸不一样。
公众号封面有封面的比例,正文插图有正文插图的比例。
如果所有 SVG 都按一个尺寸输出,要么封面别扭,要么正文图别扭。
这时候就需要规则。
说“规则系统”听起来挺正式,其实在这个工具里,它就是几行朴素判断:文件名像封面,就按封面尺寸;其他�图,就按默认尺寸。
不过这里我没有搞复杂规则引擎,也没有设计什么插件系统。没必要。
需求很简单:按文件名匹配不同尺寸。
{
"rules": {
"cover": {
"match": ["封面*.svg", "*cover*.svg"],
"width": 2350,
"height": 1000
},
"default": {
"match": ["*.svg"],
"width": 3200,
"height": 1800
}
}
}
这个设计很土,但好用。
封面文件按 cover 规则输出,其他文件按 default 规则输出。规则从上到下匹配,谁先命中用谁。
这就够了。
小工具最怕什么?
最怕你刚想解决一个小问题,手一抖,给自己设计了一个平台。
本来只是想转几张图,最后搞出插件机制、任务队列、Web UI、权限系统。功能是多了,问题也变多了。等你终于写完,文章都过气了。
所以这里的取舍是:刚好够用。
文件名匹配不完美,但它顺手、够用、划算。
这三个词,基本就是我评价这类工具的顺序。
这里的提示词也不用装得很高级:
现在配置文件能用了,但我发现封面图和正文插图需要不同尺寸。
你帮我在配置里加一个简单的规则:像封面的文件按封面尺寸输出,其他 SVG 按正文图尺寸输出。规则不用复杂,按文件名匹配就行。
转换时最好能显示每个文件用了哪个规则。
第五版:补 README,给未来的自己留条活路
最后一步是补 README。
很多人觉得 README 是给别人看的。
不完全是。
大量个人工具的 README,首先是写给未来的自己看的。
你今天写完脚本,觉得所有东西都记得住。两周后再打开,只会看到一个 render.js、一个 config.example.json,然后开始问自己:这个命令怎么跑来着?配置路径是相对谁?输出目录会不会自动创建?失败了看哪里?
人类的大脑很擅长忘记自己写过的小工具。
所以 README 不是面子工程,是续命文档。
svg-renderer 的 README 里记录了这些东西:
npm install
node render.js --config "C:\path\to\render.config.json"
还说明了:
-
inputDir是 SVG 输入目录。 -
outputDir是 PNG 输出目录。 -
rules用来匹配不同图片尺寸。 -
当前只支持 PNG。
-
执行完成后看
success和failed。
这些内容看起来都很普通。
但普通不代表不重要。
一个工具有没有后续生命力,很多时候就差这几行说明。
没有 README 的小工具,像没贴标签的充电线。你知道它有用,但每次用之前都得先猜一遍它到底给谁充电。
最后这一步,我会直接让 OpenCode 帮我补文档:
这个工具现在基本能用了。
你帮我补一份 README,写清楚它是干什么的、怎么安装依赖、怎么运行、配置文件怎么写、成功和失败怎么看。
不用写得很正式,就按未来的我隔一段时间再回来用,也能看懂的标准来写。
这过程中 OpenCode 到底帮了什么
这篇文章的重点不是 svg-renderer 本身。
它真正想讲的是:这种小任务里,OpenCode 怎么参与,人才不会被它带着跑偏。
我的分工大概是这样。
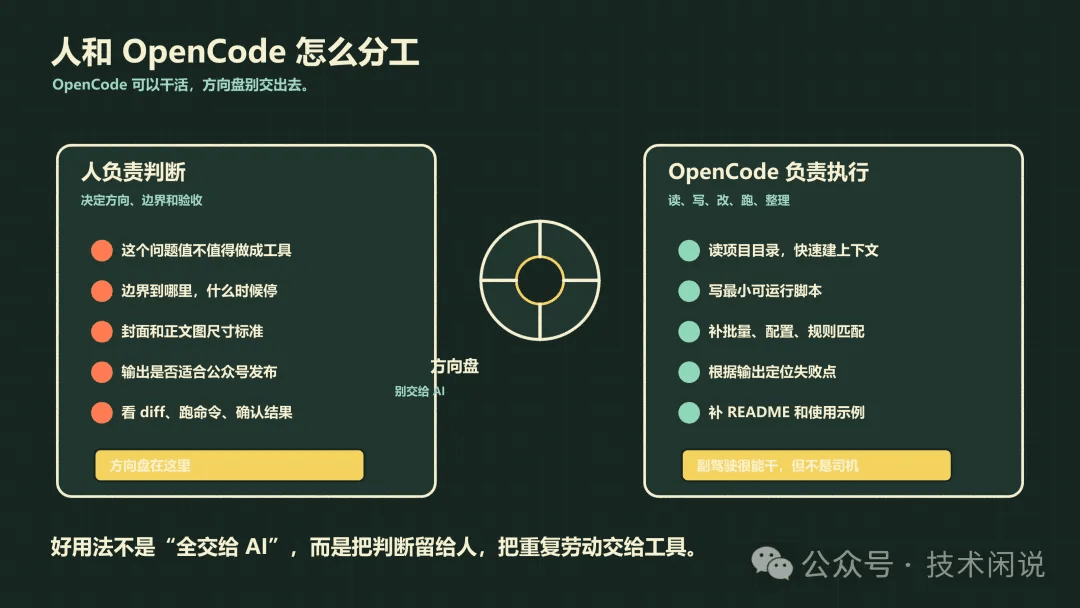
OpenCode 适合做这些事:
-
读项目目录,快速了解已有文件。
-
根据需求拆小任务。
-
写最小可运行脚本。
-
补批量处理、配置解析、规则匹配这些边界逻辑。
-
根据命令输出定位失败点。
-
补 README,把用法写清楚。
这些事交给 OpenCode 很顺手。
因为它不怕重复,不怕读文件,不怕整理结构,也不怕把一堆零散说明写成文档。
但人必须负责这些事:
-
判断问题值不值得做成工具。
-
决定工具边界,不让它膨胀。
-
决定封面和正文图的尺寸标准。
-
判断输出图片是否适合公众号发布。
-
看 diff,跑命令,确认结果。
换句话说,OpenCode 可以干活,但方向盘别交出去。
我在这类任务里通常不会说“帮我做一个完善的图片转换工具”。这个说法太大,容易把任务带歪。我会说得更窄一点:先读一下这个目录,帮我把这些 SVG 转成 PNG;能跑通以后,再考虑要不要批量、要不要配置、要不要补 README。
尤其是这种小工具,很容易被“顺手再加一个功能”带跑。
今天加 JPG,明天加 WebP,后天加批量压缩,再后天加上传 CDN。听起来都合理,但它们不一定服务当前需求。
我的判断是:先把 SVG 到 PNG 这条链路做好。
够用就停。
停,也是一种工程能力。
跑起来,看输出,失败了别装没看见
写代码这件事,最不能省的是验证。
OpenCode 写完脚本以后,我不会只看它说“已完成”。我会看文件、看 diff、跑命令。
这一步听起来啰嗦,但它是人控场的关键。AI 最容易让人偷懒的地方,就是它说得太像真的了。你要是不跑一下,很容易把“看起来合理”当成“已经可用”。
第六篇实际使用时,命令是这样的:
node render.js --config "C:\Users\andy1\work\公众号创作\5.1opencode使用系列教程第6篇\render.config.json"
跑完以后看输出:
DONE success=6 failed=0
这比任何“我已经帮你完成了”都可靠。
如果有失败,也别急着让 AI 再生成一版。
先看失败信息。
是配置文件路径错了?输入目录不存在?SVG 文件读不出来?规则没匹配上?还是 sharp 渲染失败?
问题要先归因,再修。
这也是我用 OpenCode 时反复强调的一点:不要把它当许愿池。
你说“修一下”,它当然会修。�但它修的是不是根因,就要看你有没有让它先把问题查清楚。
小任务最适合练 OpenCode 的工作流
为什么我选 svg-renderer 这个小工具来写第七篇?
因为它刚好完整。
它有真实需求,有明确输入,有明确输出,有代码实现,有命令验证,有 README 收尾。
这比很多大而空的演示项目更适合练 OpenCode。
如果你刚开始把 OpenCode 用进日常开发,我不建议一上来就丢给它一个大系统。
比如“帮我重构整个权限模块”“帮我优化这个项目架构”“帮我加一个完整工作流引擎”。这些任务不是不能做,而是变量太多。上下文、边界、风险、验证成本都会迅速膨胀。
更好的练习对象,是这种小而完整的任务:
-
把一个临时脚本整理成工具。
-
给一个已有工具补配置文件。
-
给一个重复命令加批处理。
-
修一个能复现的小 bug。
-
给一个内部工具补 README 和示例。
这类任务范围小,但闭环完整。
你能练到 OpenCode 的关键工作流:给上下文、拆任务、改代码、跑验证、看输出、补文档。
这些能力练熟了,再去做更大的任务,心里才有底。
最后给一份真实开发任务检查表

如果你也想用 OpenCode 做一个真实小任务,可以照着这份检查表走。
-
这个需求是不是来自真实重复劳动?
-
输入是什么?输出是什么?成功标准是什么?
-
有没有先让 OpenCode 读项目,而不是上来就改?
-
任务有没有拆成几个小步骤?
-
每一步是不是都能单独验证?
-
有没有看 diff?
-
有没有跑命令、测试或最小验证?
-
失败输出有没有认真看,而不是直接重试?
-
有没有补 README、示例或使用说明?
-
这个工具下次还能不能被你自己用起来?
最后一条很关键。
很多代码不是写不出来,是活不过下一次使用。
如果一个工具只能在你刚写完的当天跑通,过几天就没人知道怎么用,那它更像一次性脚手架,不像工具。
当然,一次性脚手架也不是罪。
但你要知道自己在写什么。
svg-renderer 对我来说,就是一个从一次性脚本慢慢长成可复用小工具的例子。
它没有多高级,但很真实。
OpenCode 在里面也没有扮演什么“全自动高级工程师”。它更像一个动作很快、记性不错、愿意干脏活累活的副驾驶。
副驾驶的价值不是替你决定去哪,而是在你已经知道方向之后,帮你少绕几圈、少踩几个坑、少重复几遍无聊动作。
你给它清楚的上下文,它就能帮你少敲很多重复代码。
你给它明确的边界,它就不太容易把小工具写成大工程。
你愿意看输出、看 diff、跑验证,它就能成为一个可靠的开发助手。
工具最终拼的不是演示时有多炫。
而是你下次真的遇到麻烦时,会不会自然地把它叫出来干活。